
Low-Resource Multilingual North Germanic NMT
Our team placed first in the WMT2021 shared task in multilingual low-resource machine translation for North Germanic. The shared task asked participants to train models for translation to/from Icelandic (is), Norwegian-Bokmål (nb), and Swedish (sv). We followed a fairly typical process, though we did add a few specific small tricks in each step to boost our performance; smartly leveraging parallel and monolingual data, and employing pre-training, back-translation, fine-tuning, and ensembling, all helped our models to outperform the other submitted systems on most language directions.
The shared task description and final rankings are available here. Our paper is available in arXiv, and should be made available in the WMT20201 (EMNLP2021) proceedings once those are released. So in this blog post, I’ll give only a brief overview of the main points.
Data
The shared task was data constrained, limiting the corpora to data sets from from Opus Corpus, ELRC, and Wikipedia. Allowed languages included the target low-resource languages of Icelandic (is), Norwegian-Bokmål (nb), and Swedish (sv), as well as in the related high-resource languages of Danish (da), German (de), and English (en), which all come from the same Germanic language family. The low-resource languages were the only ones that would be scored in the shared task, so we dubbed these our “primary” languages, while the high-resource ones became our “secondary” languages, that we would only use in service of improving the primary translation directions.
The shared task was scored on thesis abstracts, and a development data set was provided with approximately 500 abstracts in each translation direction.
We downloaded all of the allowed Opus data sets, as well as all of the allowed ELRC data sets. For Opus, we just reused a very simple bash script to wget all the parallel data sets for all the corpora, e.g. for TED2020:
CWD=`pwd`
DLDIR=downloaded
mkdir -p $DLDIR/TED2020
cd $DLDIR/TED2020
OLDIFS=$IFS; IFS=','; #internal field separator
for i in da,is de,is en,is, is,nb is,sv da,nb da,sv de,sv en,nb en,sv da,en da,de de,en de,nb nb,sv; do
set -- $i;
wget https://opus.nlpl.eu/download.php?f=TED2020/v1/moses/$1-$2.txt.zip -O $1-$2.txt.zip
unzip -o $1-$2.txt.zip
done
IFS=$OLDIFS
cd $CWDFor ELRC, we used a scraper to download all of the data using the allowed language directions, which resulted in 159 corpora (retrieved May 2021).
Once we had all of this data downloaded, we deduplicated it, and removed non-translations using basic heuristics such as length discrepancy between source and target, too many non-ascii characters, and removing other languages using FastText word embeddings for language identification.
Finally, we mirrored all of the parallel data, so that our data set included all possible translation directions between all the primary and secondary languages. This ended up providing us with a little over 400 million parallel sentence pairs to train on. Some language pairs provided a lot of data while others had very little. In particular, we had too little is-nb data to include it in the training set, so our model ended up translating between the is-nb directions in a zero-shot setting.
The approximate data distribution by language pair was as follows (is-nb, nb-sv, and da-nb are so tiny that their slivers don’t show up on the pie chart):
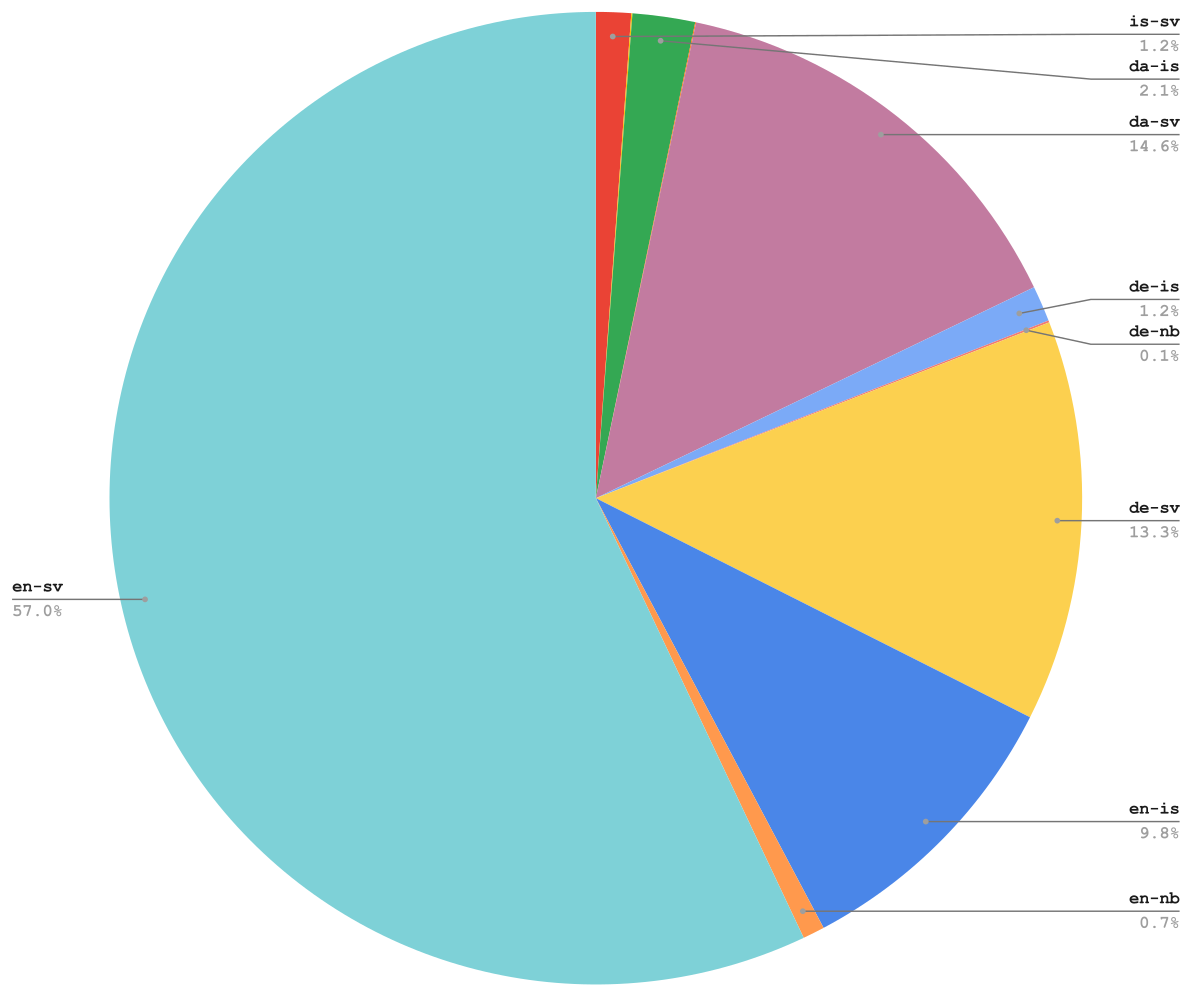
We also downloaded a dump of the monolingual Wikipedia data for Norwegian and Icelandic, skipping the Swedish, because much of that data consists of stubs and tables generated by a bot, so it isn’t the best quality. Instead, we used the Swedish side of our parallel data as a monolingual Swedish data set.
We filtered the monolingual data to be closer the the domain of the shared task by using cosine similarity between LASER sentence embeddings of the monolingual data and the development data provided by the shared task organizers.
Preprocessing
We created a shared vocabulary of 32k tokens for our models using byte-pair encoding (BPE) with SentencePiece. The BPE model was trained on data that was sampled from our parallel data set using temperature sampling over the languages. The goal of sampling in this way is to provide a compromise that allows the BPE model to view a larger portion of lower resource language tokens (unlike sampling according to the original distribution would), while still providing extra space in the model for the larger variety of tokens coming from high-resource corpora (unlike sampling uniformly would).
We also included digits in our BPE model as separate, user-defined symbols, in order to improve the translation of numerals. This encourages the model to separate each numeral into its component digits to translate them one at a time, and then those tokens are squished back together at the end, during the de-BPE postprocessing step.
Once our data was BPEd, we prepended a tag such as <2xx> to the source side, to indicate the translation direction to the model.
Training
Our baseline system was a MarianNMT model trained our our entire data set of all the language directions, stopping training when the performance ceases to improve on 15 checkpoints in a row. We used this model to back-translate our monolingual data, and filtered this synthetic parallel data for non-translations.
To create our winning “Contrastive” system, we further fine-tuned this baseline system on a concatenation of those language directions which included our low-resource languages on either the source or target side, and the back-translated data. We ensembled of the last four checkpoints of this model for the submission.
To create our second-place “Primary” system, we followed a slightly different approach. We used the mt5-base language model from Google as a pre-training method. We chose this model, firstly, because it included all of our low-resource languages, and secondly, because there was already a very easy-to-use implementation available through SimpleTransformers (which actually uses HuggingFace under the hood). In the first round, we adapted this model to the translation task, by training for 5 epochs on 100k sentences sampled from our entire data set. In the second round, we fine-tuned it again for 5 epochs on a new set of 100k sentences, sampled only from those language directions which included our low-resource languages.
Results
The results shown below (taken from our poster, which is available here), show the SacreBLEU results of our models on the shared task development and test sets. The models include:
- marian: the baseline model,
- marian_ft: the fine-tuned system before ensembling
- marian_ft_esmb: the fine-tuned system after ensembling (Contrastive submission)
- mt5_base_ada: the mt5 adapted system
- mt5_base_ada_ft: the further fine-tuned mt5 system (Primary submission)
The results are shown over the shared task development set (which we used internally for comparing model performance prior to submission), and the final shared task test set (which was what we were scored on by the shared task organizers).
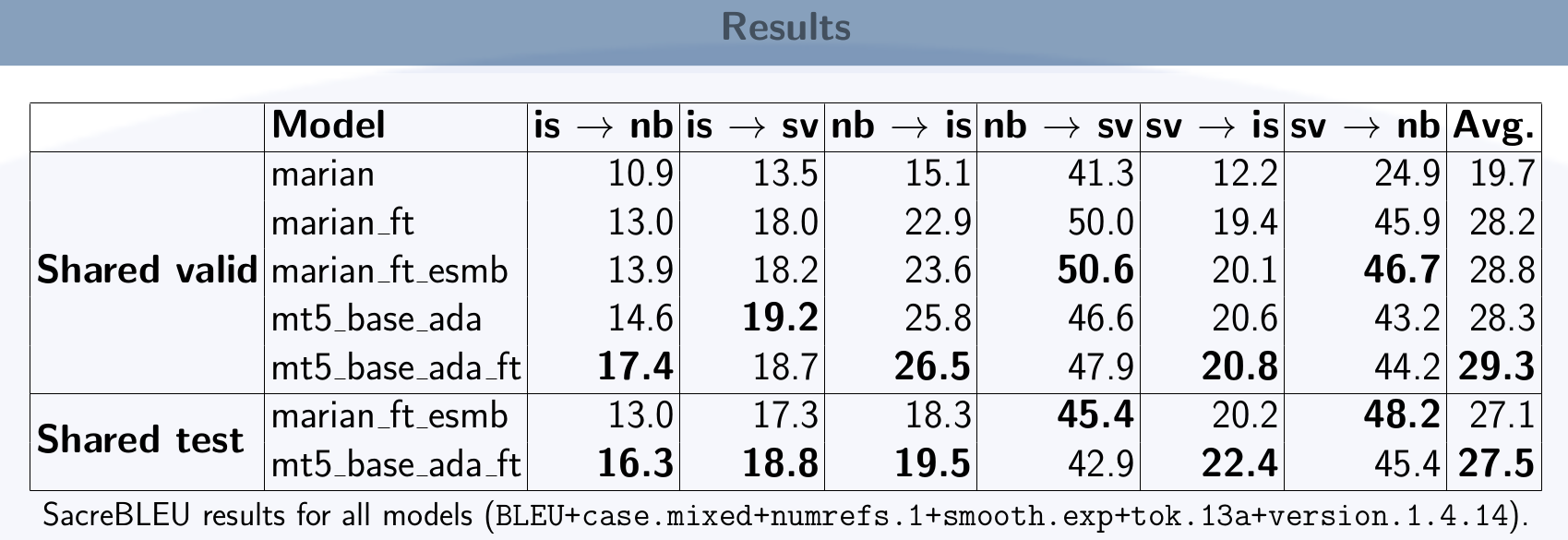
In general, we see that we always improve when we use fine-tuning and ensembling. As expected, we see the worst performance on those language directions which include our lowest resource language of Icelandic.
The two models are neck-and-neck for translation quality on the shared task test set, with the marian_ft_esmb model performing slightly better on the very similar nb-sv pair, and the mt5_base_ada_ft model performing slightly better on the other directions. I think it’s a little easier to see how close they are to each other on a polar spider plot like this one:
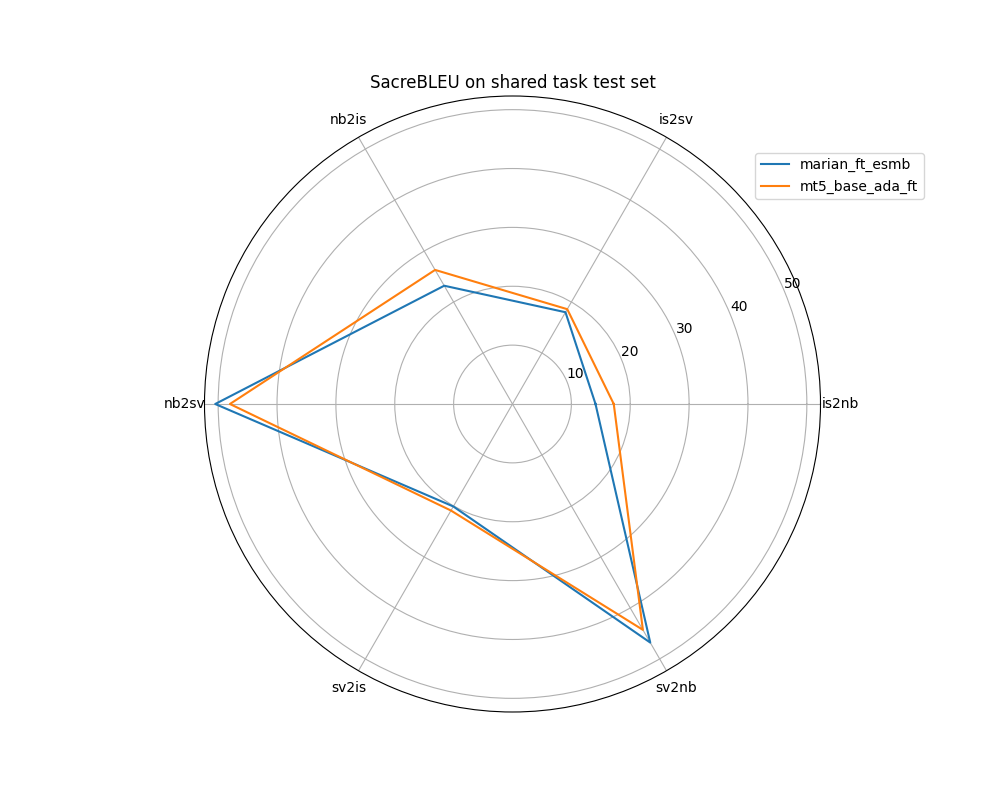
From a pure numbers standpoint, the mt5_base_ada_ft model outperforms the marian_ft_esmb model a tiny bit on average. However, the shared task used a number of different metrics to decide on the final rankings, which resulted in our marian_ft_esmb system slightly outperforming the mt5_base_ada_ft model. None of the metrics seem ideal, so in future work, it would be important to use multiple metrics for selecting models.
Overall, this was a fun project for us, though I hope that if we do a similar project in the future, we’ll have more time to explore some interesting research directions. For anyone interested in the details, I recommend you to check out our paper, and if you do find some useful nugget there, please feel free to cite it in your own work.
Cite Our Paper
Currently, the citation is only available from arXiv, since the conference proceeedings aren’t out yet. Additionally, our poster is available here.
@article{DBLP:journals/corr/abs-2109-14368,
author = {Svetlana Tchistiakova and
Jesujoba O. Alabi and
Koel Dutta Chowdhury and
Sourav Dutta and
Dana Ruiter},
title = {EdinSaar@WMT21: North-Germanic Low-Resource Multilingual {NMT}},
journal = {CoRR},
volume = {abs/2109.14368},
year = {2021},
url = {https://arxiv.org/abs/2109.14368},
eprinttype = {arXiv},
eprint = {2109.14368},
timestamp = {Mon, 04 Oct 2021 17:22:25 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2109-14368.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}Written on October 20, 2021. See a bug? Contact me on social (below).